7.1 Introduction
env는 scoping을 지원powers하는 데이터 구조이다.
이 챕터에서는 env에 대해 깊게 알아볼 것.
그 구조에 대해 깊이 있게 설명describe해보며,
이걸 이용해서, Section 6.4에서 설명된 4개의 scoping rules에 대한 이해를 증가improve
R을 그날그날 사용하는 사람들에게는, env를 이해하는게 별로 필요하지 않다.
하지만 우린 전문가니깐. 이해하는 것이 중요하다.
왜냐하면 env가,
1. lexical scoping, namespaces, R6 classes과 같은 많은 R의 특징들features을 가능케power하고,
2. evaluation과 상호 작용하게해서interact with,
dplyr나 ggplot2와 같은 domain specific languages을 만드는데 강력한 도구를 주기 때문.
Quiz
만약 다음의 질문들을 올바르게 대답할 수 있다면, 이미 이 챕터의 중요한 부분들을 아는 것이나 다름없다.
답은 Section 7.7의 마지막 부분에서 확인 가능.
- env가 list와 다른 점을 최소한 3가지 이상 나열해보라.
- global env의 parent는 무엇인가? parent가 없는 유일한 env는 무엇?
- 함수의 enclosing env란 무엇인가? 왜 중요한가?
- 함수가 호출되어진 env를 어떻게 결정할 수 있는지?
<-와<<-는 어떻게 다른지?
Outline
-
7.2에서는 env의 기본적인 특성basic properties들을 소개하고, 어떻게 너만의 것을 만들 수 있는지 보여줌
-
7.3에서는 env와 계산하는 함수 템플릿function template를 제공하고,
유용한 함수와 함께 이 아이디어를 illustrate. -
7.4에서는 특별한 목적을 위해 사용되는 env를 설명describe.
목적이라함은, packages를 위해서, 함수 내에서, namespaces를 위해서, 함수 실행function execution을 위해서 -
7.5에서는 마지막으로 중요한 env에 대해 설명. the caller environment.
이건, 어떻게 함수가 호출되는지를 묘사describe하는 call stack에 대해 배울 것을 요구.
debugging을 하기위해traceback()을 호출해봤다면, call stack을 본 적이 있을 것. -
7.6에서는 env가 다른 문제들을 해결하는데 유용한 데이터 구조인, 3가지 경우에 대해 간략히 다룸.
briefly discusses three places where envs are useful data structures for solving other problems.
Prerequisites
부수적인 디테일이 아닌, env의 에센스essence에 focus할 수 있게 도와주는 rlang 함수들이 필요.
library(rlang)
rlang 패키지에 있는 env_ 함수들은 pipe로 작업할 수 있게 설계되었다.
env를 첫 번째 인자argument로 받으며, 많은 것들이 env를 return한다.
여기서는 최대한 간단하게 보일 수 있도록 pipe를 사용하지 않을 것이나, 너만의 코드를 작성할 때는, 쓰는 것을 고려해보자.
7.2 Environment basics
일반적으로, env는 네이밍된 리스트named list와 비슷하다.
하지만 4가지의 중요한 예외가 있음.
-
모든 이름은 unique해야 함.
Every name must be unique -
env에 있는 이름들은 정렬되지 않음.
The names in an environment are not ordered. -
env는 parent가 있음.
An environment has a parent. -
env는 수정된다고 해서 copy되지는 않음.(reference semantics)
Environments are not copied when modified.
코드, 그림들과 함께 이 아이디어를 자세히 알아보자.
7.2.1 Basics
env를 만들기 위해서는, rlang::env()를 사용한다.
list() 같이 작동하는데, name-value 짝들을 세트로 받는다.
It works like list(), taking a set of name-value pairs
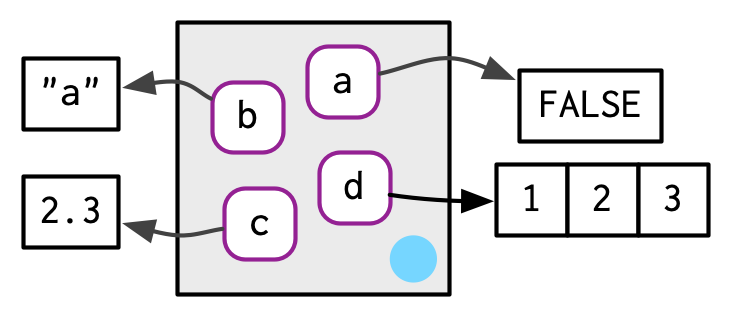
e1 <- env(
a = FALSE,
b = "a",
c = 2.3,
d = 1:3,
)
base R에서는
새로운 env를 만들기 위해서는 new.env()를 사용한다.
hash나 size같은 parameter는 무시해라. 필요없다.
값을 정의하고 생성하는 걸 동시에 할 수는 없다. 밑에 나온대로, $<-를 사용해라.
env의 일은, names 셋에다가 values 셋을 associate, 혹은 bind하는 것.
env라는 것을, 정렬되지 않은 이름들의 가방으로 생각할 수 있다.
You can think of an environment / as a bag of names, with no implied order
(env의 첫 번째 element가 무엇이냐고 묻는 것은 말이 안 됨)
(it doesn't make sense to ask / which is the first element in an environment)
이러한 이유에서, env를 다음과 같이 그려볼 것이다.
Section 2.5.2에서 다룬 것과 같이, env는 reference semantics를 가지고 있다.
environments have reference semantics.
대부분의 R 오브젝트들과는 달리, 이걸 수정하면, copy를 만들지 않고, 즉시 수정됨.
when you modify them, you modify them in place, and don't create a copy.
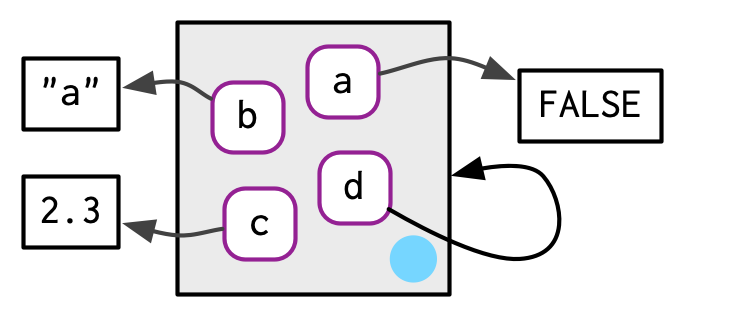
이게 무엇을 암시하냐면, envs가 그들 자체themselves를 contain할 수 있다는 것.
One important implication is that environments can contatin themselves.
e1$d <- e1
env를 프린팅해보면 그냥 메모리 주소memory address만 표시된다. 별로 쓸모가 없음.
e1
## <environment: 0x0000000013ee2ac8>
대신에 env_print()를 사용하면 좀 더 정보를 준다.
env_print(e1)
## <environment: 0000000013EE2AC8>
## parent: <environment: global>
## bindings:
## * a: <lgl>
## * b: <chr>
## * c: <dbl>
## * d: <env>
env_names()를 사용하면, 현재의 bindings를 주고 있는 캐릭터 벡터character vector를 얻을 수 있다.
You can use env_names() to get a character vector / giving the current bindings
env_names(e1)
## [1] "a" "b" "c" "d"
base R에서는
3.2.0 이후 버전에서는 names()를 사용하면, env의 bindings의 리스트를 준다.
3.1.0 혹은 그 이전 버전에서는, ls()에다가 all.names = TRUE라고 옵션을 줘야 모든 bindings를 보여줌.
이게 가끔 하던 rm(list = ls())의 의미였군.. 변수들 다 없앨 때 쓰던..
7.2.2 Important environments
Section 7.4에서 특별한 env에 대해서 자세하게 다뤄볼 것인데, 여기서는 2개만 미리 하겠다.
current env, 혹은 current_env()는, 코드가 현재 실행되고 있는 env다.
is the environment in which code is currently executing.
experimenting interactively할 때에는, 보통 그건 global env.이다. 혹은 global_env()
(역자: 어떻게 해석해야할지 모르겠음. 그러니깐 그냥 우리가 평소 쓰는 그것이 global env라는 것 같은데.
원문: When you're experimenting interactively, that's usually the global environment, or global_env().)
global env는 가끔 workspace라고 불린다. 왜냐하면 이 곳에서 모든 interactive 계산이 일어나기 때문.
interactive( = outside of a function)
그러니깐 내가 이해를 해본대로 써보자면,
우리가 이 때까지 늘상 해왔던 단순한 계산, 할당 이런 것들이 다 interactive computation인데,
이게 일어나는 곳이 global env이고, worskpace임.
env들을 비교하기 위해서는, ==가 아닌, identical()을 이용해야 한다.
왜냐하면 ==는 벡터화된 연산자vectorised operator인데, env는 벡터가 아니기 때문이다.
identical(global_env(), current_env())
## [1] TRUE
global_env() == current_env()
## Error in global_env() == current_env(): atomic과 리스트 타입들에 대해서만 비교(1)가 가능합니다
base R에서는
global env는 globalenv()를 통해서, current env는 environment()를 통해서 접근 가능.
global env는 Rf\_GlobalEnv 혹은 .GlobalEnv로 프린트된다.
7.2.3 Parents
모든 env는 parent를 가지고 있다. 또다른 env임.
다이어그램에서, parent는 작은 옅은 파란색 원으로 표시되고, 또다른 env를 화살표로 가리키고 있다.
In diagrams, the parent is shown as a small pale blue circle and arrow that points to another env.
parent는 lexical scoping을 implement하기 위해 사용된 것.
만약에 env 안에서 name이 발견되지 않는다면, R은 그것의 parent를 확인해볼 것이다.
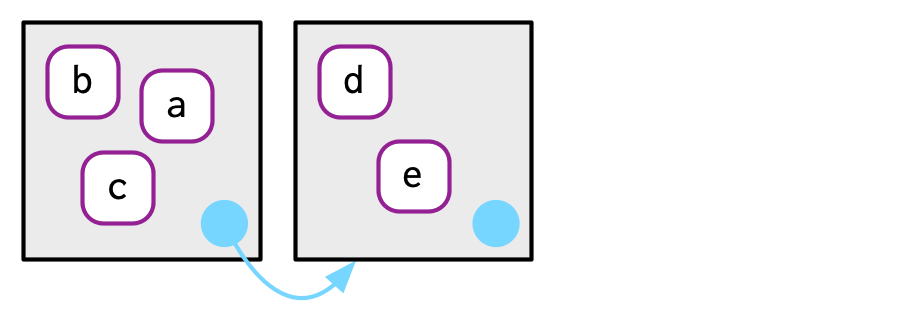
env()에서 unnamed argument를 공급해줌으로써, parent env를 설정할 수 있다.
만약에 공급해주지 않는다면, 디폴트로 current env가 된다. current env가 parent env가 된다는 뜻
아래의 코드에서, e2b의 parent는 e2a이다.
e2a <- env(d = 4, e = 5)
e2b <- env(e2a, a = 1, b = 2, c = 3)
공간을 아끼기 위해, ancestors를 다 그리진 않을거다.
그냥 옅은 파란색 원을 볼 때마다, parent env가 어딘가에 있다는 것만 기억해라.
화살표가 향한 곳이, parent env.
env의 parent를 env_parent()를 통해서 찾을 수 있다.
env_parent(e2b)
## <environment: 0x0000000018bfbdb0>
env_parent(e2a)
## <environment: R_GlobalEnv>
그런데 딱히 e2a라고 딱 나오는게 아니고, 주소가 같게 나온다.
env_print()에서 찾을 수 있던 주소.
그거랑 같게 나옴.
parent가 없는 단 하나의 env가 있다. empty env.
텅 비어있는 파란색 원을 가지고 있는 애인데, 얘가 R_EmptyEnv다. 이건 R이 사용하는 이름임.
공간이 허락할 때만 이 empty env를 그려놓겠다.
e2c <- env(empty_env(), d = 4, e = 5)
e2d <- env(e2c, a = 1, b = 2, c = 3)
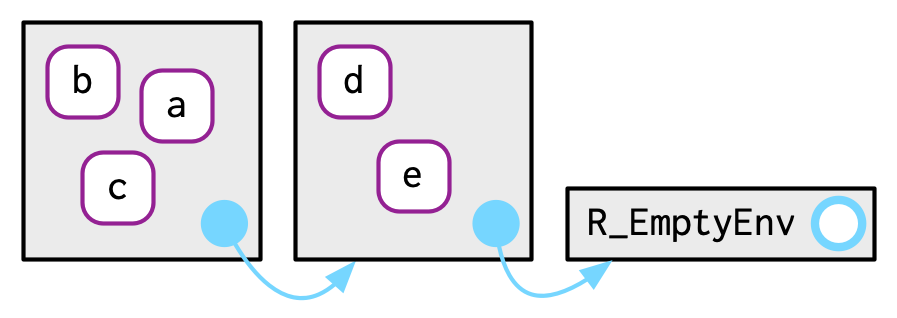
모든 env의 ancestors는 결국에는, empty env와 함께 종료된다.
env_parents()를 이용해서 모든 ancestors를 볼 수 있다.
env_parents(e2b)
## [[1]] <env: 0000000018BFBDB0>
## [[2]] $ <env: global>
env_parent(e2d)
## <environment: 0x00000000190c05c0>
디폴트로, env_parents()는 global env에 다다르면 멈춘다.
global env의 ancestors는 모든 attach된 패키지를 포함하고 있기 때문에, 이게 유용하다.
env_parents()의 디폴트를, empty env까지 찾게끔 바꿔보면 이걸 확인해볼 수 있다.
Section 7.4.1에서 이 env들을 다시 확인해볼 것이다.
env_parents(e2b, last = empty_env())
## [[1]] <env: 0000000018BFBDB0>
## [[2]] $ <env: global>
## [[3]] $ <env: package:rlang>
## [[4]] $ <env: package:stats>
## [[5]] $ <env: package:graphics>
## [[6]] $ <env: package:grDevices>
## [[7]] $ <env: package:utils>
## [[8]] $ <env: package:datasets>
## [[9]] $ <env: package:methods>
## [[10]] $ <env: Autoloads>
## [[11]] $ <env: package:base>
## [[12]] $ <env: empty>
base R에서는
parent.env()를 사용해서 env의 parent를 찾는다.
모든 ancestors를 return해주는 그런 base 함수는 없음.
7.2.4 Super assignment, <<-
env의 ancestors는, <<-와 중요한 관계가 있다.
The ancestors of an environment / have an important relationship to <<-.
보통의 할당regular assignment, <-는, 항상 current env에서 변수를 생성create한다.
Regular assignment, <-, always creates a variable in the current env.
Super assignment, <<-는 절대 current env에서 변수를 생성하지는 않고,
대신에 parent env에서 발견된, 존재하는 변수를 수정한다.
but instead modifies an existing variable / found in a parent env.
x <- 0
f <- function() {
x <<- 1
}
f()
x
## [1] 1
만약, <<-가 존재하는 변수를 찾지 못한다면, global env에서 하나 만들 것이다.
이건 보통 원치 않은 것인데, 왜냐하면 global 변수는 함수들 간의 뚜렷하지 않은 의존성을 유발하기 때문.
This is usually undesirable, because global variables introduce non-obvious dependencies btw functions.
<<-는 대부분 보통 function factory와 함께 사용될 것이다. Section 10.2.4에서 다룸.
7.2.5 Getting and setting
리스트 때와 같은 방법으로, $와 [[를 이용해서 env의 elements를 get, set할 수 있다.
e3 <- env(x = 1, y =2)
e3$x
## [1] 1
e3$z <- 3
e3[["z"]]
## [1] 3
하지만 [[를 숫자 인덱스와는 쓸 수 없고, [도 사용할 수는 없다.
(env에서는 order가 없다고 했으니깐 뭐)
e3[[1]]
## Error in e3[[1]]: wrong arguments for subsetting an environment
e3[c("x", "y")]
## Error in e3[c("x", "y")]: 객체의 타입 'environment'는 부분대입할 수 없습니다
$와 [[는 만약 binding이 존재하지 않는다면, NULL을 return할 것이다.
에러를 얻길 원한다면, env_get()를 사용해라.
e3$xyz
## NULL
env_get(e3, "xyz")
## Error in env_get(e3, "xyz"): 객체 'xyz'를 찾을 수 없습니다
binding이 존재하지 않는 경우에, 디폴트값을 얻도록 설정해놓을 수도 있다.
default 인자argument를 사용해라.
env_get(e3, "xyz", default = NA)
## [1] NA
env에다가 bindings를 추가할 수 있는 2가지 방법이 있다.
- env_poke()는 name(string으로 주어야함)과 value를 받는다.
env_poke(e3, "a", 100)
e3$a
## [1] 100
env_bind()는 여러 개의 값들을 bind할 수 있도록 해준다.
env_bind(e3, a = 10, b = 20)
env_names(e3)
## [1] "x" "y" "z" "a" "b"
binding 추가하는것에 대해봤고,
env가 binding을 갖고 있는지를 env_has()를 통해서 확인할 수 있다.
env_has(e3, "a")
## a
## TRUE
리스트와는 다르게, element를 NULL로 설정한다고 해서 제거가 되는건 아니다.
왜냐하면 가끔씩 NULL을 refer하는 이름을 원할 수 있기 때문에.
이럴 때는 env_unbind()를 사용해라.
e3$a <- NULL
env_has(e3, "a")
## a
## TRUE
env_unbind(e3, "a")
env_has(e3, "a")
## a
## FALSE
name을 unbinding하는 것은, 오브젝트를 삭제하지는 않는다.
그건 garbage collector의 일이고, 이름이 묶여있지 않은 오브젝트들은 자동적으로 삭제하는 애들.
이 작업은 Section 2.6에 자세하게 설명되어 있다.
base R에서는
get(), assign(), exists(), rm()을 봐보아라.
이것들은 current env와 interactively하게 사용할 수 있도록 디자인되어 있다.
그래서 다른 env들과 작업할 때는 좀 투박하다.
그리고 inherits 인자argument에 대해서 알아두어라.
이건 디폴트로 TRUE인데, 기본 환경base equivalents에서,
제공supplied된 env와 이 env의 모든 ancestors를 검색inspect할 것이라는 뜻.
7.2.6 Advanced bindings
env_bind()의 이색적 변형exotic variants가 2개 더 있다.
env_bind_lazy()는 delayed bindings를 만든다.
접근이 처음으로 되었을 때, evaluated되는 애들.
더 자세하게 살펴보면, delayed bindings는 promises를 만드는데, 그래서 함수 인자들과 같이 행동behave한다.
Behind the scenes, delayed bindings create promises, so behave in the same way as function arguments.
그러니깐 호출이 되어서 정말 필요할 때까지는 evaluate하지는 않는 것임.
env_bind_lazy(current_env(), b = {Sys.sleep(1); 1})
system.time(print(b))
## [1] 1
## user system elapsed
## 0.00 0.00 1.01
system.time(print(b))
## [1] 1
## user system elapsed
## 0 0 0
그러니깐 처음에는 접근하는데 Sys.sleep()의 값만큼 시간이 걸렸는데, 한 번 evaluated이 되고 난 이후에는
바로바로 접근access이 가능.
delayed bindings의 가장 중요한 사용은 autoload()에서 이루어진다.
R 패키지가 데이터셋을 제공할 수 있도록 해주는 것이 autoload().
메모리에 로드되어있는 것처럼 행동behave하는데, 사실은 필요할 때에만 디스크에서 로드되는 것.
env_bind_active()는 active bindings를 만든다. 얘들은 접근될 때마다 re-computed
env_bind_active(current_env(), z1 = function(val) runif(1))
z1
## [1] 0.2718428
z1
## [1] 0.233198
active bindings는 R6의 active fields를 implement할 때 사용된다. Section 14.3.2에서 배우게 됨.
base R에서는
?delayedAssign()과 ?makeActiveBinding()을 보아라.
7.2.7 Exercises
7.3 Recursing over environments
하나의 env의 모든 ancestors를 조작operate하고 싶다면, 보통 recursive 함수를 작성하는게 편리하다.
이 섹션에서는 env에 대해 새롭게 배운 지식을 적용해서,
name을 받는 함수를 작성하는데, 그 name이 어디에 정의되어있는지 env를 찾는 것을,
R의 regular scoping rules를 이용해 where()로 찾아본다.
This section shows you how, applying your new knowledge of environments to write a function
that given a name, finds the environment where() that name is defined, using R's regular scoping rules.
이해가 안 되어도 쭉쭉 읽어보고 다시 읽어보자.
where()의 정의는 단순straightforward하다.
2개의 arguments를 가지며, 하나는 찾아볼 name(문자열string으로),
다른 하나는 어떤 env에서부터 찾아볼지.
(여기 나오는 caller_env()가 왜 좋은 디폴트인지 7.5에서 배우게 될 것)
where <- function(name, env = caller_env()){
if (identical(env, empty_env())) {
# Base case
stop("Can't find ", name, call. = FALSE)
} else if (env_has(env, name)) {
# Success case
env
} else {
# Recursive case
where (name, env_parent(env))
}
}
3가지 케이스가 있다.
- base case: empty env까지 다다랐는데 binding을 못 찾은 것.
더 갈 곳이 없어서 error가 나옴. - successful case: env에 name이 존재해서, env를 return
- recursive case: env에서 이름이 발견되지 않아서, parent를 시도해봄.
이 3가지 케이스들을, 3개의 예시와 함께 illustrate해보자.
where("yyy")
## Error: Can't find yyy
x <- 5
where("x")
## <environment: R_GlobalEnv>
where("mean")
## <environment: base>
그림을 통해 보면 좀 더 이해가 쉬울 수도 있다.
다음의 코드와 다이어그램 같이, 2개의 envs가 있다고 상상해보자.
e4a <- env(empty_env(), a = 1, b = 2)
e4b <- env(e4a, x = 10, a = 11)
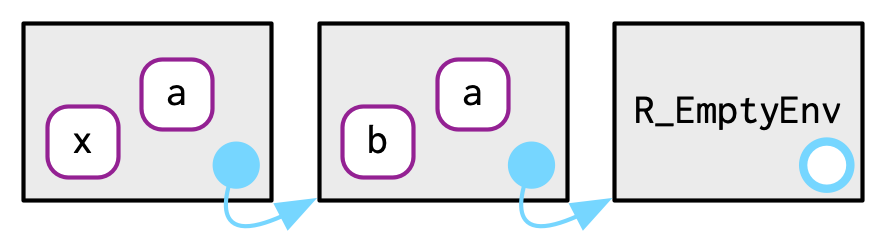
where("a", e4b)는e4b에서a를 찾을 것.where("b", e4b)는e4b에서b를 못 찾아서, parent인e4a에서 찾아볼 것이고, 거기서 찾음.where('c", e4b)는e4b에서 찾아보고,e4a에서 찾아보고, empty env에 다다라서 error를 throw.
envs들에 대해서는 반복적으로recursively 작업하는 것은 자연스럽다.
그래서 where()을 유용한 템플릿으로 쓸 수 있다.
where()에서 특정한 것들만 빼면 구조를 좀 더 명확하게 볼 수 있다.
f <- function(..., env = caller_env()) {
if (identical(env, empty_env())) {
# Base case
} else if (success) {
# Success case
} else {
# Recursive case
f (..., env = env_parent(env))
}
}
Iteration versus recursion
위에 한 recursion 대신에 루프를 쓰는 것도 가능하다.
내 생각에는 recursive version이 더 쉬운 것 같은데,
만약에 recursive functions를 많이 안 써봤다면 이게 더 쉽게 이해될 수도 있기에, 해보았다.
f2 <- function(..., env = caller\_env()) { while (!identical(env, empty\_env())) { if (success) { \# success case return() } \# inspect parent env <- env\_parent(env) }
# base case
}
7.3.1 Exercises
7.4 Special environments
대부분의 env는, 니가 만드는게 아니고, R에 의해 만들어진다.
이 섹션에서는, 대부분의 중요한 env에 대해서 배울 것이다.
위에서는 이미 current env랑 global env를 배워봤었고.
패키지 env에서부터 시작해서,
그러고나서 함수가 만들어졌을 때, 함수에 bound되는 function env에 대해서 배울 것이다.
You'll learn about the function environment bound to the function when it is created,
그리고 function이 호출될 때마다 만들어지는, ephemeral execution env에 대해서 배울 것.
and the ephemeral execution environment created every time the function is called.
1. package env, 2. function env, 3. execution env
마지막으로, package와 function env가 namespaces를 지원support하기 위해 어떻게 interact하는지,
이걸로, 유저가 어떤 다른 패키지를 로드하던 간에, 패키지가 항상 같은 방식으로 작동behave한다는 걸 보장받을 수 있다.
7.4.1 Package env와 search path
library()나 require()를 통해서 attach한 패키지들은 global env의 parents들 중 하나가 된다.
immediate parent는 가장 최근에 attach한 패키지, 그리고 그 바로 위 parent는 2번 째로 최근에 attach한 패키지..이런 식 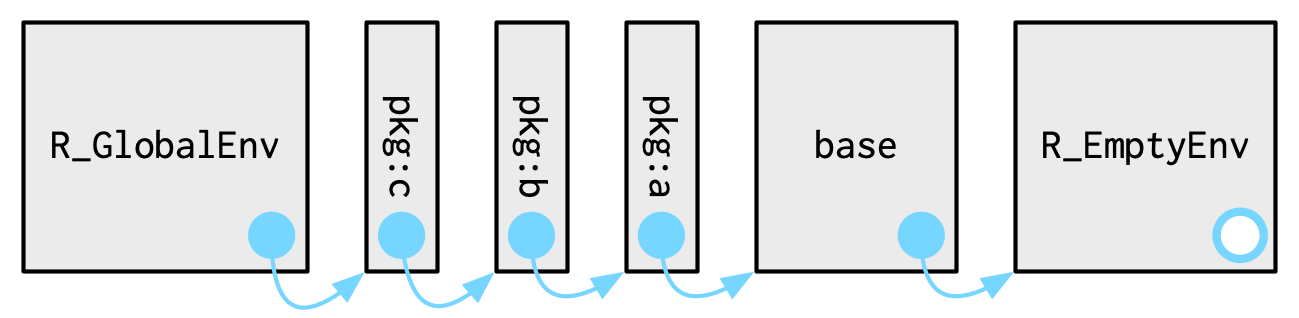
이런 식으로 parents를 거슬러 올라가다보면, 패키지들이 attach된 순서를 볼 수 있다.
이걸 search path라고 부르는데,
이 env들에 있는 모든 오브젝트들을 top-level interactive workspace에서부터 찾을 수 있기 때문.
because all objects in these environments / can be found from the top-level interactive workspace.
이 env들의 이름들을, base::search()를 통해서 혹은 env 그 자체들을 rlang::search_envs()를 통해서 확인할 수 있다.
search()
## [1] ".GlobalEnv" "package:rlang" "package:stats"
## [4] "package:graphics" "package:grDevices" "package:utils"
## [7] "package:datasets" "package:methods" "Autoloads"
## [10] "package:base"
search_envs()
## [[1]] $ <env: global>
## [[2]] $ <env: package:rlang>
## [[3]] $ <env: package:stats>
## [[4]] $ <env: package:graphics>
## [[5]] $ <env: package:grDevices>
## [[6]] $ <env: package:utils>
## [[7]] $ <env: package:datasets>
## [[8]] $ <env: package:methods>
## [[9]] $ <env: Autoloads>
## [[10]] $ <env: package:base>
search path의 마지막 2개 env들은 항상 같다. Autoloads 그리고 package:base
-
Autoloadsenv는 delayed bindings를 이용해서 메모리를 save한다.
어떻게? 패키지 오브젝트들(예를 들어, 큰 데이터셋)을 필요할 때만 로딩하는 방식으로. -
package:base혹은 그냥 base라고 하는 base env는, base 패키지의 env다.
이건 다른 패키지들의 로딩을 시동걸 수 있어야하기 때문에 특별하다.
It is special because / it has to be able to bootstrap / the loading of all other packages.
이 base env는,base_env()를 통해 직접적으로 access할 수 있다.
library()를 통해서 다른 패키지를 로딩할 때, global env의 parent env가 다음과 같이 변한다.
pkg:d가 추가된 것. 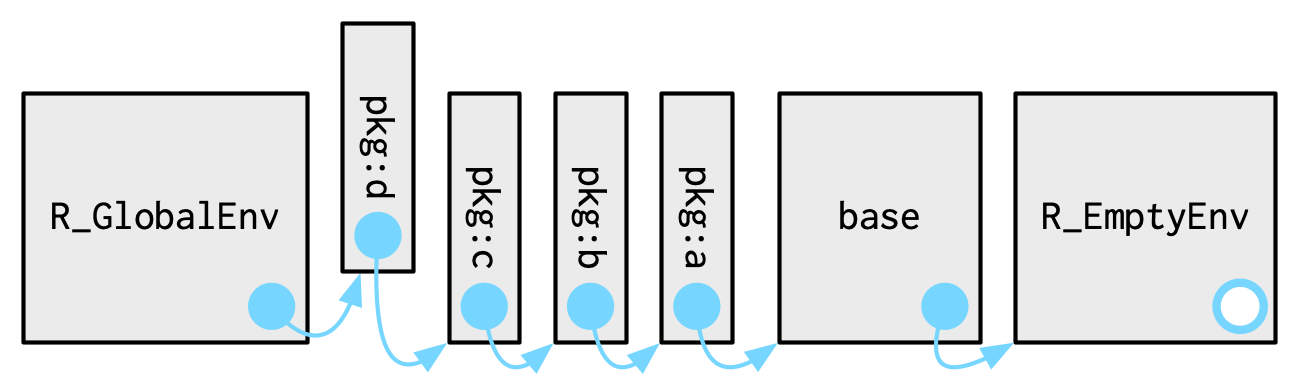
7.4.2 The function environment
함수function는, 그게 만들어질 때, current env를 bind한다.
A function binds the current environment when it is created.
이걸 function env라고 부르는데, lexical scoping에 사용된다.
컴퓨터 언어에서는, 자신의 env를 캡쳐하는 함수들을 closures라고 부르는데, R에서는 함수가 자기자신의 env를 항상 bind한다.
그래서 R's documentation에서는 function이랑 closures랑 혼용해서 사용하는 것이다.
이 function env는 fn_env()를 통해서 얻을 수 있다.
y <- 1
f <- function(x) x + y
fn_env(f)
## <environment: R_GlobalEnv>
base R에서는
함수 f의 env를 access하고 싶다면 environment(f)를 사용해라.
다이어그램에서는, 함수를 다음과 같이 env를 bind하고 있는 '반원이 붙은 네모'로 그릴 것이다.
In diagrams, I'll draw a function as a rectangle with a rounded end that binds an environment.
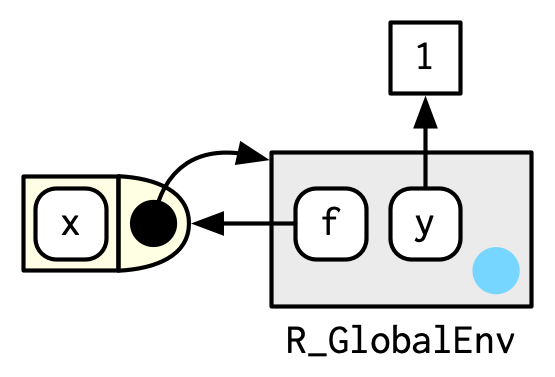
이 경우에 f()는, f라는 이름을 함수에 bind하는 env를(왼쪽으로 향한 화살표), bind한다.(오른쪽으로 향한 화살표)
In this case, f() binds the environment that binds the name f to the function.
(이 부분 이해하는게 여간 어려운 일이 아니다...화이팅해보자)
하지만 항상 이런건 아니다. 다음의 예를 보자.
g()는 global env를 binds하고 있고, g는 새로운 env e에 bound되어 있다.
(아래로 향한 화살표), (왼쪽으로 향한 화살표)
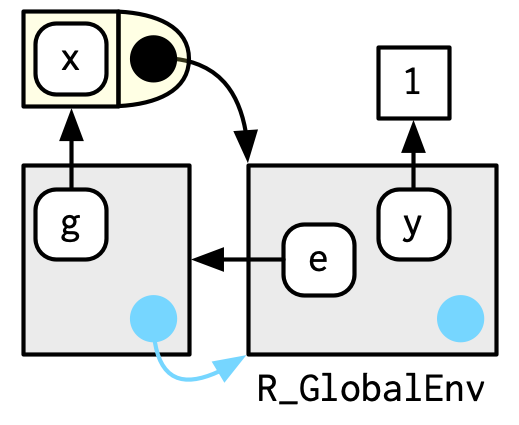
bind하는 것과 bound되는 것은 미묘하지만 분명한 차이가 있다.
전자는 우리가 g를 어떻게 찾느냐 하는 것이고, 후자는 g가 그것의 변수들을 어떻게 찾느냐 하는 것임.
함수 g는 global env에서 우리가 찾는 것이고, g의 변수들이 있다면 e라는 env안에서 찾는 것.
7.4.3 Namespaces
위의 다이어그램을 보면, 어떤 패키지들을 로드시키냐에 따라 패키지의 parent env가 달라진다.
그럼 걱정이 된다. 패키지들이 다른 순서로 로드되어 있으면 패키지가 다른 함수를 찾는게 아닐까?
namespaces의 목표는 이런 일이 생기지 않도록 하는 것이다.
그리고 어떤 패키지들이 attach되었던간에 같은 방식으로 작동하도록.
예를 들어서, sd()를 봐보자.
sd
## function (x, na.rm = FALSE)
## sqrt(var(if (is.vector(x) || is.factor(x)) x else as.double(x),
## na.rm = na.rm))
## <bytecode: 0x000000001938d7c8>
## <environment: namespace:stats>
sd()는 var()의 관점으로 정의되어 있다. sd() is defined in terms of var().
그래서 만약에 global env에서, 혹은 다른 attach된 패키지 안의, var()이라고 불리는 어떤 함수에 의해,
sd()의 결과가 영향받지 않을까 걱정할 수 있다.
so you might worry that the result of sd() / would be affected / by any function called var()
either in the global env, or in one of the other attached packages. 예를 들어,
sd(1:2)
## [1] 0.7071068
이 값을, var()을 새롭게 정의해놓는다면 바뀌지 않을까? 하고 걱정할 수 있음.
var <- function(x) x
var(1)
## [1] 1
이제 var()이라는 함수는 받은 그대로를 출력하는 함수
그래도 여전히 sd()는 바뀌지 않는다.
sd(1:2)
## [1] 0.7071068
R은 앞서 설명한 함수 대(對) binding env를 이용해서, 이러한 문제를 피한다.
R avoids this problem by taking advantage of the function versus binding env described above.
패키지에 있는 모든 함수들은, 한 쌍의 env와 결합associate되어 있다.
package env와 namespace env.
-
package env는 패키지에 대한 외부 인터페이스.
The package env is th external interface to the package.
R user가 어떻게 attach된 패키지에서, 혹은::를 이용해서 함수를 찾는지.
It's how you, the R user, find a function in an attached package or with::.
package env의 parents는 search path에 의해 결정된다.
즉, 패키지가 어떤 순서로 attach되었는지에 따라, package env의 parents가 결정된다. -
namespace env는 패키지에 대한 내부 인터페이스.
package env가, 우리가 어떻게 함수를 찾는지를 컨트롤한다면,
namespace env는 어떻게 그 함수가 그 안의 변수를 찾는지를 컨트롤.
정리해보면, package env는 우리가 함수를 찾을 때 쓰는 것이고, namespace env는 함수가 그 안의 변수를 찾을 때 쓰는 것이고.
근데 그렇다면, 어떤 함수가 다른 함수들을 찾을 수는 없는 것 아닌가?
내가 함수를 찾을 수는 있고, 함수가 그 안의 변수들을 찾을 수는 있는데,
함수가 다른 함수들을 찾을 수는 없잖아?
그래서,
package env에 있는 모든 binding들은 namespace env에도 있다.
이렇게 모든 함수들이, 패키지 안의 다른 함수들을 사용할 수 있는 것.
하지만 몇몇 binding들은 namespace env에서만 출현occur한다.
이것들은 internal 혹은 non-exported 오브젝트들이라고 알려져있는데, 이것들 때문에
user가 내부 구현internal implementation을 감출 수 있는 것hide이다.
이걸 그림으로 나타내보면,
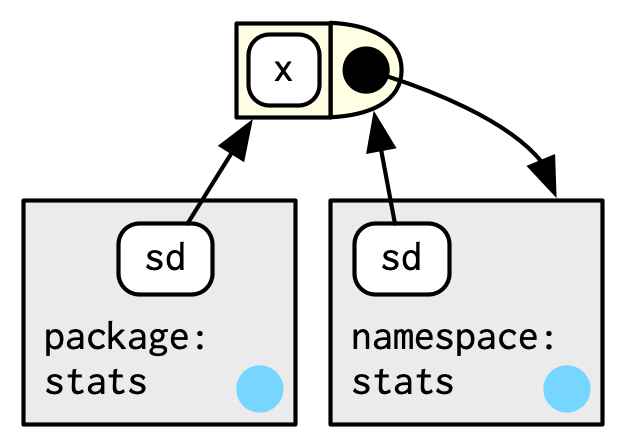
package env랑 namespace env가 둘 다 sd에 binding을 갖고 있는데, sd() 함수는 namespace env를 binds.
나는 이게 이해가 안 돼요.
하, 근데 이걸 위에서 했던,g()라는 함수와 e라는 env의 예에 대입시켜보면 매치가 안 된다. 그 그림에서,
①
g()는 global env를 binds하기에, global env에서 g()를 찾음. ②
g는 e에 bound되어 있어, its variable을 e에서 찾는다는데,
바로 위 그림을 보면, ①
sd()라는 함수는 namespace env를 binds하고 있다는데, 얘는 package env에서 찾는다고 했음. ②
sd는 package env에 bound되어 있으니, its variable은 여기서 찾아야 하는데, namespace env에서 찾는게 맞음.
그러니깐 내 생각엔, binds하는 곳에서 변수를 찾는거고, bound되는 곳에서 이 함수를 찾을 수 있는거라고 이해하겠다.
정말 오랫동안 생각했는데, 이게 맞는거 같다.
원문의 7.4.3 Namespaces 직전에 나오는 문장, The distinction between binding and being bound by is subtle but important, the difference is how we find
g versus how g finds its variables. 이 문장이 잘못된거 같다.
다음으로, 모든 namespace env는 같은 set의 ancestors를 갖는다.
-
각 namespace는 imports env를 갖는다.
패키지에 이용된 모든 함수들에 대한 bindings를 갖고 있는 env.
imports env는 패키지 개발자에 의해,NAMESPACE파일로 컨트롤된다. -
모든 base 함수들을 explicit하게 importing하는 것은 귀찮다.
그래서 imports env의 parent는 base namespace.
base namespace는 base env와 같은 bindings를 갖고 있는데, 다른 parent를 갖는다. -
base namespace의 parent는 global env다. 이 말인즉슨, binding이 imports env에서 정의되지 않았다면, 패키지는 평소와 같은 방법으로 찾아볼 거라는 것.
This means that if binding isn't defined in the imports env / the package will look for it in the usual way.
이건 보통 나쁜 방법이기 때문에,R CMD check가 자동적으로 이러한 코드에 대해서 경고한다.
S3 메소드 디스패치가 작동하는 방법 때문에 필요했던 역사적인 이유가 있다.
위 3가지 논의를 그림으로 정리해보면, 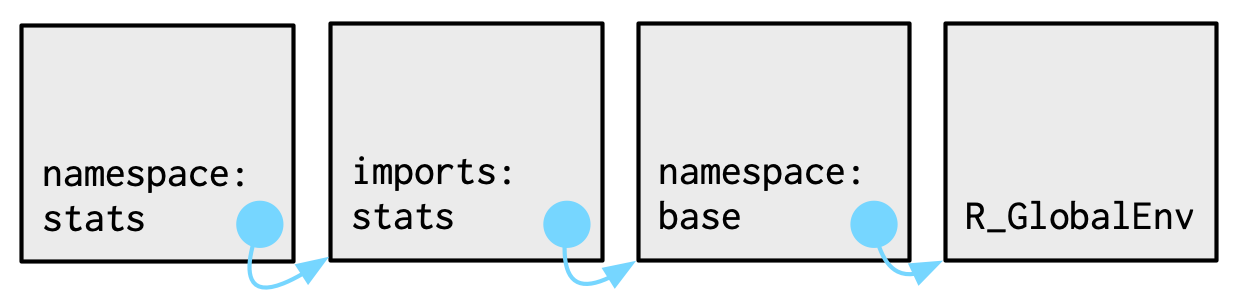
그리고 이걸 전부다 종합해서, sd()의 예를 설명해보면, 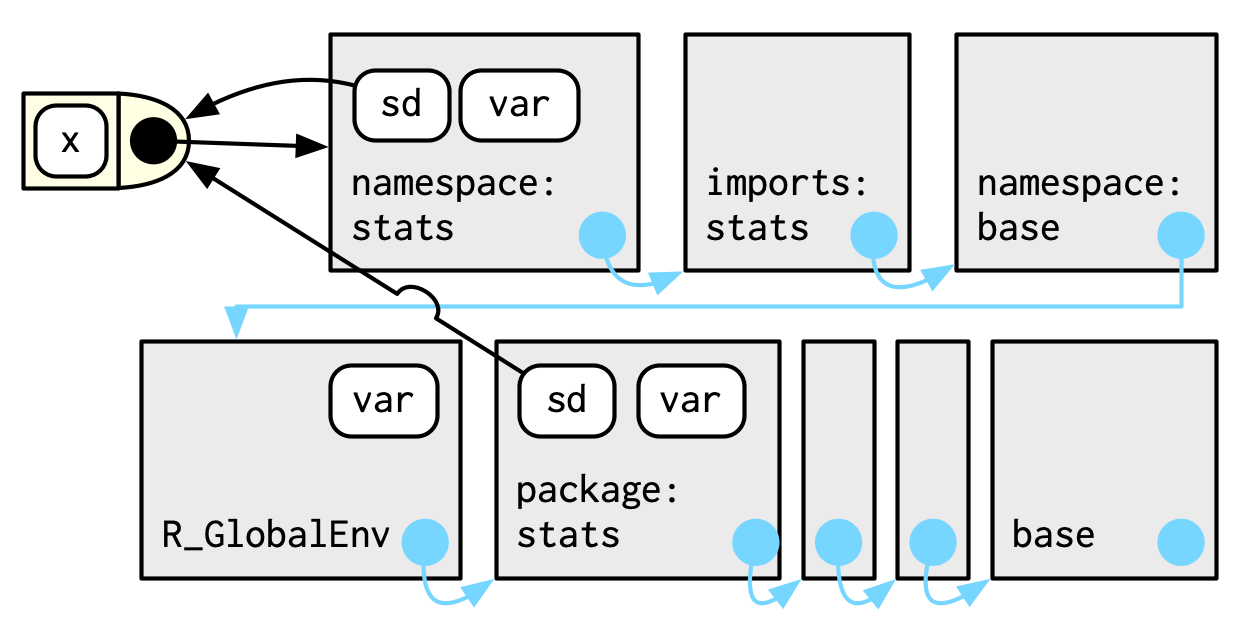
그래서 sd()가 var의 값을 찾아볼 때, 항상 패키지 user가 아닌, 패키지 developer가 결정해놓은 env의 sequence들을 찾아가게 된다.
그래서 package 코드는 user가 어떤 패키지들을 attach시켜놨던간에 항상 같은 방식으로 작동하도록 보장받는 것이다.
개인적인 정리
그러니깐,sd()라는 함수를 밖에서 호출할 때는, bound되어 있는 package env에서 찾게 되고, 얘는 Global env의 parent env임. 그래서, 내가
var()이라는 함수를 외부에서 어떻게 정의를 해놓던간에 얘를 찾아보지 않게 되는 것임. 그래서 내가 임의로어떻게 정의가 되었던간에, 일관적인 결과를 얻게됨.
가끔 package들을 로드시켰는데 이름이 같아서 문제가 될 때도 있다.
R많이 써본 사람이면 한번쯤 겪었을텐데,
select()였나..? filter()였나 뭐 하나가 충돌이 되어서 이상한 결과값이나 에러를 얻었던 적이 있다. 이건 이제 진짜 로드되는 순서에 따라 원하는 결과가 나올수도 있고, 아닐수도 있는거지. 흠 이해가 된다.
위 그림을 보면 알다시피 패키지와 namespace env간에 직접적이 연관direct link은 없다.
function env를 통해서만 연관은 정의된다.
7.4.4 Execution environments
마지막으로 다뤄야할 중요한 주제는 execution env다.
다음의 함수를 처음 실행시켜보면 무엇이 나올까? 2번째로 실행시켜보면?
g <- function(x) {
if (!env_has(current_env(), "a")) {
message("Defining a")
a <- 1
} else {
a <- a + 1
}
a
}
계속 읽기전에 한 번 생각해보자.
g(10)
## Defining a
## [1] 1
g(10)
## Defining a
## [1] 1
이 함수는 같은 값을 계속 return하는데, Section 6.4.3에서 다루었던 fresh start principle 때문이다.
함수가 호출될 때마다 host execution에 새로운 env가 생긴다.
이건 execution env라고 부르고, 이것의 parent는 function env다.
좀 더 간단한 예와 함께 이 과정을 설명해보자.
execution env는 function env를 통해 찾을 수 있다.
h <- function(x) {
a <- 2
x + a
}
y <- h(1)
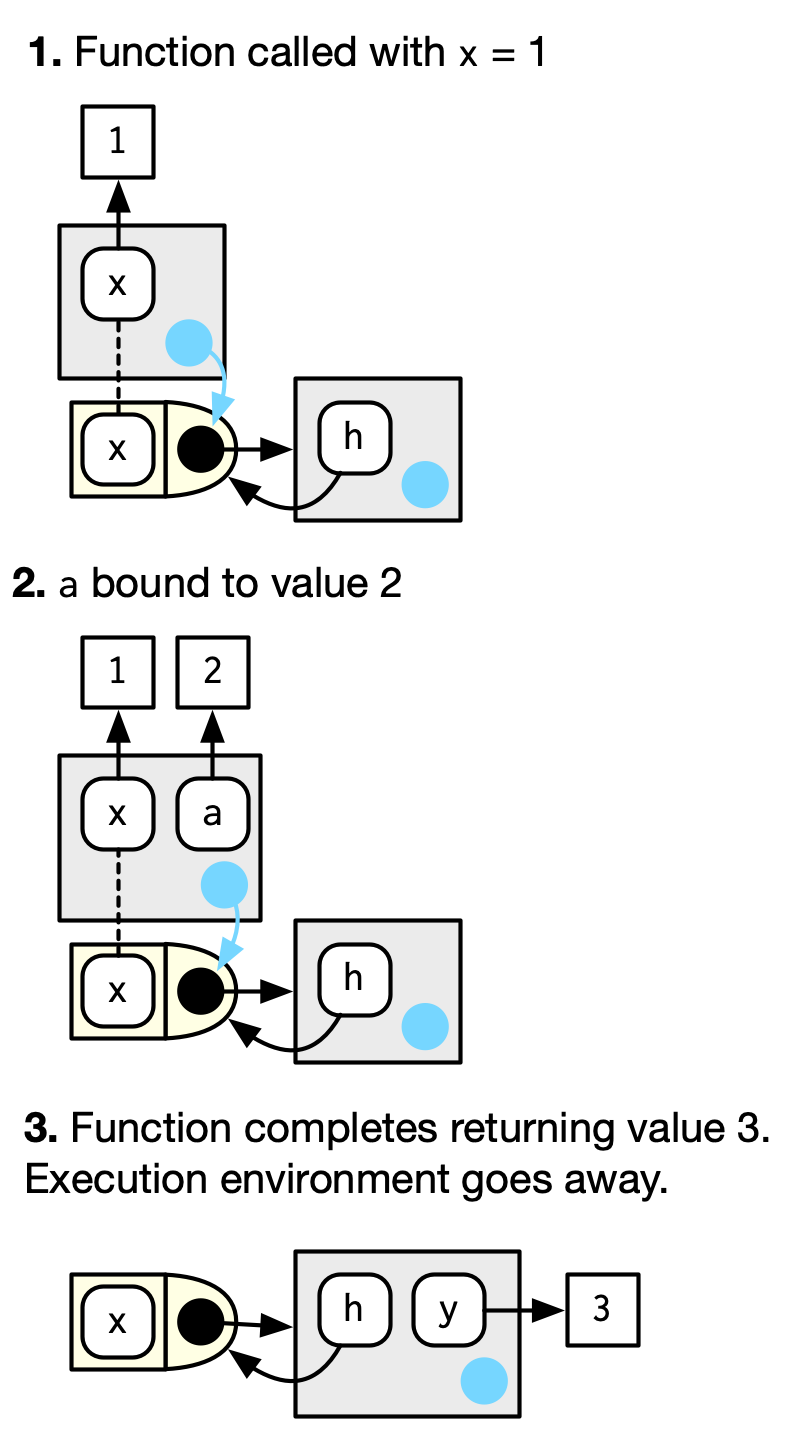
- 에서처럼, 우리가
y <- h(1)이라고 함수를 호출하면, execution env가 생겨서x에다가 1을 assign. - 에서처럼, 이 execution env안에서
a에다가 2를 assign. - 에서처럼, execution env는 사라지고,
y에다가 3을 return하면서 함수가 complete.
그림에서, execution env의 parent가 function env라는 것을 확인할 수 있다.
execution env는 보통 ephemeral하다. 쓰고나면 없어진다.
함수가 완료되고 나면, env는 garbage collected된다.
몇 가지 방법으로 이걸 더 오래남게끔 할 수는 있다.
첫 번째는 explicit하게 return하는 것.
h2 <- function(x) {
a <- x * 2
current_env()
}
e <- h2(x = 10)
env_print(e)
## <environment: 0000000018AEE958>
## parent: <environment: global>
## bindings:
## * a: <dbl>
## * x: <dbl>
fn_env(h2)
## <environment: R_GlobalEnv>
여기서도 h2의 execution env의 parent가 global env라는 걸 볼 수 있다.
function env가 global env이기 때문.
두 번째 방법은 함수같이, env가 binding된 object를 return하도록 하는 것.
Another way to capture it is to return an object with a binding to that environment, like a function.
다음의 예는 function factory를 사용해서 이 아이디어를 illustrate한다.
plus()라는 function factory를 이용해서, plus_one()이라는 함수를 만들어볼 것임.
plus <- function(x) {
function(y) x + y
}
plus_one <- plus(1)
plus_one
## function(y) x + y
## <environment: 0x00000000185f2d00>
다이어그램을 보면, plus_one()의 enclosing env가 plus()의 execution env라서 조금 복잡하다. 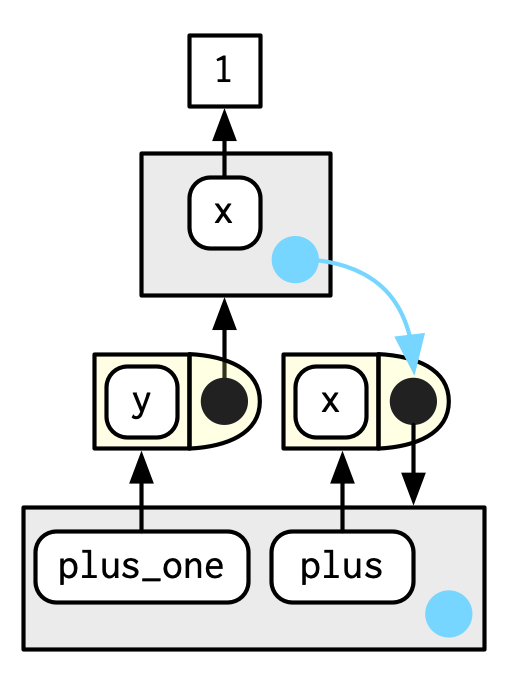
우리가 plus_one()을 호출하면 무슨 일이 일어나는지?
plus_one()의 execution env는, 캡쳐된 plus()의 execution env를 parent로 가질 것이다.
What happens when we call plus_one()?
Its execution environment will have / the captured execution env of plus() as its parent.
그래서 plus()의 execution env가 더 오래 남아있다. 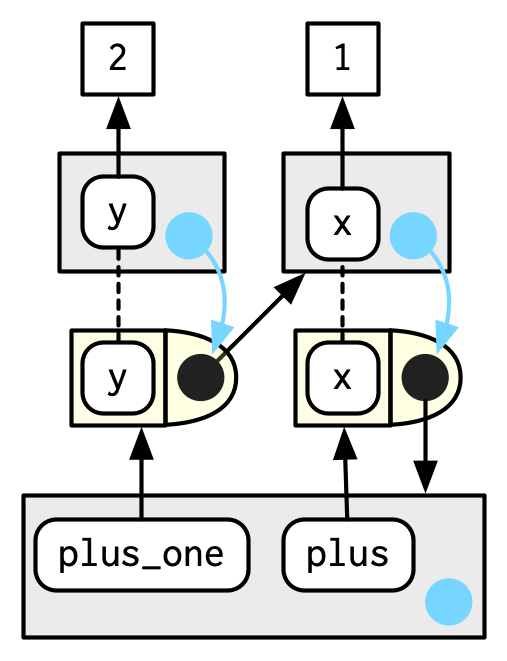
function factory에 대해서는 Section 10.2에서 자세하게 배운다.
7,4,5 Exercises
7.5 Call stacks
마지막으로 설명해야할 env는, caller env.
rlang::caller_env()로 access할 수 있다.
함수가 호출되는 곳의 env를 공급해준다. 그래서 함수가 어떻게 호출되어지느냐에 따라 달라진다. 함수가 어떻게 만들어지에 따라 달라지는게 아니고.
위에서 봤듯이, env를 argument로 받는 함수를 작성할 때, 유용한 디폴트이다.
base R에서는
parent.frame()이랑 caller\_env()와 같은 것이다. 이름은 frame인데, frame이 아니라 env를 return한다.
caller env를 충분히 이해하기 위해서는, 2개의 연관된 개념들concepts을 다루어야 한다.
①frame으로 만들어진 ②call stack.
함수를 실행하는 것은, 2가지 타입들의 context를 만든다.
Executing a function creates two types of context.
이미 하나는 배웠다. execution env.
이건 function env의 child. 그리고 이건 함수를 어디에 만들어지는지에 따라 결정된다.
또 다른 하나는 call stack. 얘는 함수를 어디에 호출되어지는지에 따라 결정됨.
그러니깐, 함수를 실행하는데 있어, 어디서 호출하는지, 그리고 어디에 호출하는지에 따라,
전자는 call stack을, 후자는 execution env를. 이렇게 2가지의 타입의 context가 만들어짐.
7.5.1 Simple call stacks
간단한 sequence of calls를 illustrate해보자: f()는 g()를, g()는 h()를 call한다.
f() calls g() calls h().
f <- function(x) {
g(x = 2)
}
g <- function(x) {
h(x = 3)
}
h <- function(x) {
stop()
}
R에서 call stack을 가장 흔하게 보는 경우는, error가 발생했을때 traceback()을 살펴보는 것이다.
f(x = 1)
## Error in h(x = 3):
traceback()
## No traceback available
call stack을 이해하기 위해서,
stop() + traceback()을 쓰기보다는, lobstr::cst()를 사용할 것이다.
여기서 cst는 call stack tree의 줄임말.
h <- function(x) {
lobstr::cst()
}
f(x = 1)
## x
## 1. \-global::f(x = 1)
## 2. \-global::g(x = 2)
## 3. \-global::h(x = 3)
## 4. \-lobstr::cst()
이걸 보면, cst()는 h()로부터 호출되었고, h()는 g()로부터 호출되었고,
g()는 f()로부터 호출되었음을 알 수 있다.
traceback()에 나온 것과는 역순이라는 것을 인지할 것.
call stacks가 복잡해질수록,
sequence가 끝나는 지점이 아니라 시작하는 지점으로부터 따지는게 더 쉽다고 생각한다.
즉, "f()가 g()를 호출한다"가 "g()가 f()에 의해 호출된다"보다 쉬움.
7.5.2 Lazy evaluation
위의 call stack은 간단하다.
tree-like 구조가 관련되어 있다는 힌트가 있고, 모든게 하나의 branch에서 일어난다.
while you get a hint that there's some tree-like structure involved, everything happens on a single branch.
이게, 모든 arguments들이 eagerly evaluated되었을 때 call stack의 전형.
lazy evaluation이 연관된 좀 더 복잡한 예를 만들어보자.
함수들의 sequence를 만들어 볼 건데, a(), b(), c()는 모두 x라는 argument를 차례로 넘겨준다.pass along
a <- function(x) b(x)
b <- function(x) c(x)
c <- function(x) x
a(f())
## x
## 1. +-global::a(f())
## 2. | \-global::b(x)
## 3. | \-global::c(x)
## 4. \-global::f()
## 5. \-global::g(x = 2)
## 6. \-global::h(x = 3)
## 7. \-lobstr::cst()
x는 lazily evaluated되기 때문에, tree가 2개의 branches를 갖는다.
첫 번째 branch에서는, a()가 b()를 호출하고, b()가 c()를 호출함.
두 번째 branch에서는, c()가 argument인 x를 evaluate할 때 시작됨.
이 argument는 새로운 branch에서 evaluate되는데,
이게 evaluate되는 env가 global env이지, c()의 env가 아니기 때문이다.
7.5.3 Frames
call stack의 각 element는 frame이다. evaluation context라고도 알려져 있음.
frame은 매우 중요한 내부 데이터 구조internal data structure인데, R 코드는 데이터 구조의 작은 부분만 access할 수 있다.
왜냐하면 간섭tampering하면 R과 충돌하기 때문. it will break R.
하나의 프레임은 3개의 key components가 있다.
- 함수 호출을 하는 expression(
expr으로 라벨됨).traceback()이 프린트하는게 이것. - environment(
env라고 라벨됨), 보통 함수의 execution env.
2개의 주요한 예외가 있다.
global frame의 env는 global env.
그리고eval()을 호출하는 것도 frame을 만드는데, env는 아무것이나 될 수 있다. - parent, call stack의 이전 call(회색 화살표로 생긴거)
Figure 7.2는 Section 7.5.1에서 f(x = 1)을 호출하는데 stack을 illustrate해준다.
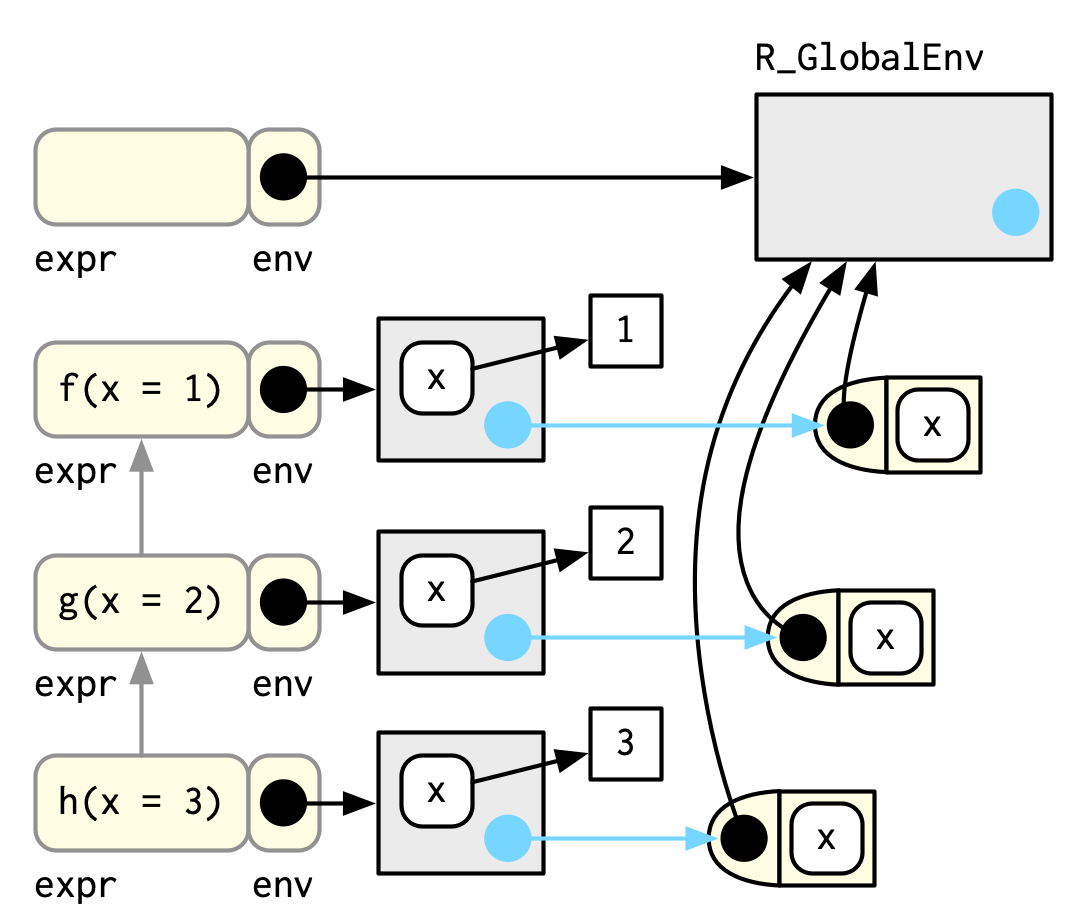
(calling environment에 focus할 수 있도록, global env에서 f, g, h로의 bindings는 생략)
프레임은, on.exit()으로 만들어진, exit handler도 가지고 있다.
얘는 컨디션 시스템을 재시작하고 조절하며, 함수가 완료되었을 때 return()을 한다.
(하 번역이 안 된다.)
원문:
The frame also holds exit handler created with on.exit(),
restarts and handlers for the condition system, and which context to return() to when a function completes.
이건 R 코드로는 접근할 수 없는 중요한 내부 디테일이다.
7.5.4 Dynamic scope
enclosing env이 아닌, calling stack에서 변수들을 찾아보는 것을 dynamic scoping이라고 부른다.
소수의 언어들만이, dynamic scoping을 implement해놨다.(Emacs Lisp는 주목할만한 예외notable execption)
왜냐하면 dynamic scoping은, 어떻게 함수가 작동하는지 추론reason about하기 힘들게끔 만들기 때문이다.
어떻게 그게 정의되었는지 뿐만 아니라, 그것이 호출되는 문맥context도 알아야한다.
Dynamic scoping은 interactive data analysis를 지원하는 함수를 개발하는데 우선적으로 유용.
이건 20장에서 다룰 주제다.
7.5.5 Exercises
7.6 As data structures
scoping을 지원하는 것만 아니라, env는 reference semantics를 가지기 때문에, 그 자체로도 유용한 데이터 구조다.
이게 해결하는데 도움을 줄 수 있는, 3가지 일반적인 문제들이 있다.
-
large data copies를 만들지 않는다. Avoiding copies of large data.
env는 reference semantics를 가지기 때문에, 절대 실수로 copy를 만들지 않는다.
하지만 bare env를 작업하기는 힘들기 때문에, R6 오브젝트 사용하는 걸 추천한다.
env위에 만들어진 것으로, 14장에서 배울 것이다. -
패키지내에서 state를 관리한다. Managing state within a package.
explicit env는 패키지 내에서 유용하다.
왜냐하면 함수 호출들에 걸쳐, state를 유지maintain하도록 해주기 때문.
일반적으로, 패키지 내의 오브젝트는 잠겨있어서locked, 직접적으로 수정할 수는 없다.
대신에 이런 식으로 할 수는 있다.
my_env <- new.env(parent = emptyenv())
my_env$a <- 1
get_a <- function() {
my_env$a
}
set_a <- function(value) {
old <- my_env$a
my_env$a <- value
invisible(old)
}
setter 함수가 old value를 return하는 것은 좋은 패턴이다.
왜냐하면 이렇게 하면 on.exit()을 사용해서 이전 값을 재설정reset하는게 더 쉽기 때문.(Section 6.7.4)
- hashmap으로 사용.
hashmap은 O(1)이라는 상수constant를 받는 데이터 구조.
O(1)은 해당 이름으로 오브젝트를 찾는데 걸리는 시간.
environments는 이 behavior을 디폴트로 사용해서, hashmap을 simulate하는데 사용할 수 있다.
이 아이디어에 대한 개발을 보고 싶다면, hash 패키지(Brown 2013)를 봐라.
7.7 Quiz answers
-
문제: env가 list와 다른 점을 최소한 3가지 이상 나열해보라.
답
4개가 있다.
이름이 unique해야함. 순서가 없음. reference semantics를 갖고 있고, env는 parents를 가질 수 있음.
-
문제: global env의 parent는 무엇인가? parent가 없는 유일한 env는 무엇?
답
가장 최근에 attach한, 로드한 package.
parent env가 없는 유일한 env는 empty env.
-
문제: 함수의 enclosing env란 무엇인가? 왜 중요한가?
답
그 함수가 생성된 env가 enclosing env. 어디에서 변수를 찾아볼건지를 결정함.
being bound.
-
문제: 함수가 호출되어진 env를 어떻게 결정할 수 있는지?
How do you determine the environment from which a function was called?답
caller_env()나parent.frame()을 사용할 것.
어떻게 함수를 호출했느냐에 따라 달라지는, 함수가 호출된 env를 제공.
이게 caller env. Section 7.5 첫 부분을 보자.
-
문제:
<-와<<-는 어떻게 다른지?답
<-는 항상 현재의 env에서 binding을 만듬.
<<-는 현재 env의 parent에 있는, 존재하는 이름을 rebind해줌.
없으면 global env에다가 하나 만들었고.